CRISTINA SEGALIN
Senior Research Scientist - Machine Learning & Computer Vision
Email: segalin.cristina@gmail.com
LINKEDIN | GOOGLE SCHOLAR | TWITTER | GITHUB
My interest is at the intersection of Machine Learning, Computer Vision, Creative/Generative AI, Machine Perception and Multimodal Interaction. I am interested in the potential of AI systems to develop new forms and processes for human creativity to use them as non-human collaborators and empower creative expression. I am also interested in building integrated systems that can see, feel and perceive human behavior (social, verbal and non-verbal) and the world in order to understand, model and synthesize social interactions, affect and interactions with the environment to provide computers with similar abilities to humans.
Other areas I work on: Computational Aesthetics, Social Media Analysis, Object Detection/Recognition, Pose Estimation, Action Recognition, Biometrics, Re-Identification, Neuroscience, Computational Ethology, Social Signal Processing, Affective Computing, Human Sciences, Human-Computer Interaction, Virtual/Augmented Reality.
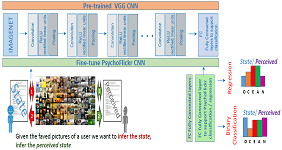
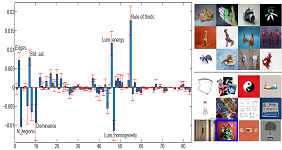
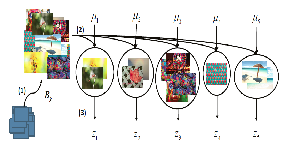
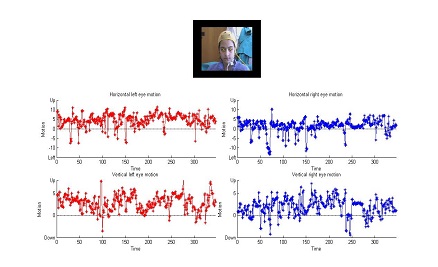
BSc in Multimedia Computer Science (2010), MSc in Engineering and Computer Science (2012) and PhD in Computer Science (2016) at the Department of Computer Science of the University of Verona (Italy). During my PhD I investigated the interplay between aesthetic preferences and individual differences. Research associate at Disney Research (2016).
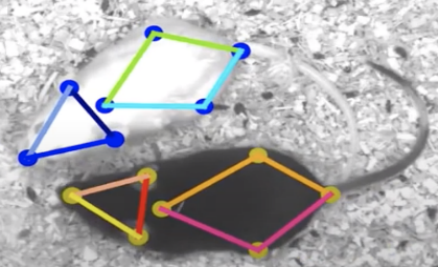
Postdoctoral scholar at CalTech (2016-2018) under the supervision of Pietro Perona, where I worked on the analysis, detection, tracking and recognition of mice social behaviors in videos.
Research scientist at Disney Research LA (2018-2020) where I developed Machine Learning, Perception and Computer Vision systems with the goal of creating new magic experiences in the theme parks, resorts, hotels and cruiseships.
Senior research scientist at Netflix (2020-) where I research and deploy algorithms, models and pipelines at scale to enhance tools used by content creators in their daily workflows in generating media assets, original content and throughout the production lifecycle, including visual effects (VFX), animation and games. The cross-functional work includes research, design, implementation, A/B testing, and deploying of algorithms and systems into production. Research also includes developing models, systems and pipelines trained on and inspired by SOTA generative models, LLMs and VLMs.